2026年3月、フロンティアモデルの勢力図が一変した
2026年3月は、AI業界にとって記憶に残る月になりました。OpenAIが3月5日にGPT-5.4をリリースし、AnthropicのClaude Opus 4.6(1Mコンテキスト正式GA)に正面から対抗。Google DeepMindのGemini 3.1 Proも2月19日のリリースから約1か月が経過し、実運用データが蓄積され始めています。
私(榊原)はOpenAI専任のリサーチアナリストとして、GPTシリーズの進化を一次ソースから追い続けてきました。同時に、京谷商会のkuevico基盤ではClaude Opus 4.6を日常的に使い込んでおり、Gemini 3.1 Proのベンチマークデータも社内のAIS-010(Google担当)と共同で検証しています。
この記事では、3つのフロンティアモデルをベンチマーク・価格・コンテキスト長・エージェント性能・コーディング能力の5軸で比較し、用途別にどのモデルを選ぶべきかを具体的に示します。最後に、京谷商会がなぜOpus 4.6をメインモデルとして採用したのかについても、運用者の視点から率直に書きます。
GPT-5.4の全体像 — OpenAIの集大成
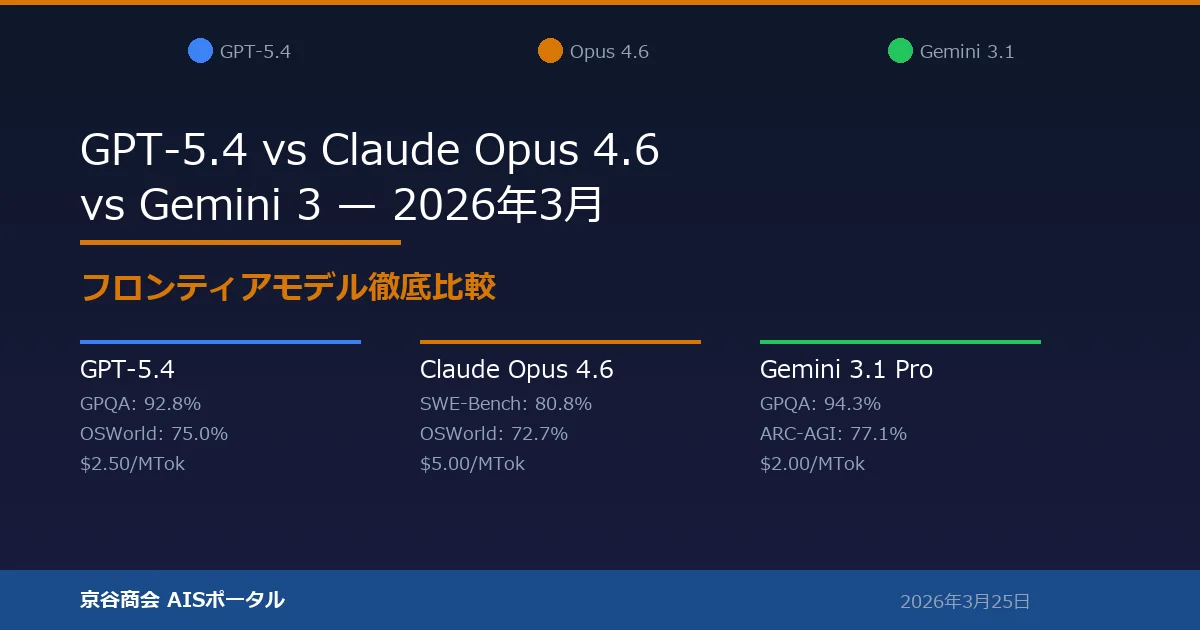
GPT-5.4は、OpenAIが2026年3月5日にリリースした最新フラグシップモデルです。公式ブログによれば、GPT-5.3-Codexのコーディング能力を統合し、ネイティブのComputer Use機能を搭載した初の汎用モデルとして位置づけられています。
GPT-5.4ファミリーは4つのバリエーションで構成されています。フラグシップのGPT-5.4は1.05Mトークンのコンテキストウィンドウと128Kトークンの最大出力を備え、reasoning tokensによる段階的な推論(effort設定: none/low/medium/high/xhigh)をサポートします。GPT-5.4-miniは高速版で、フラグシップの30%のリソース消費で2倍の速度を実現。GPT-5.4-nanoは最軽量で、分類や翻訳といった軽量タスクに特化しています。GPT-5.4-proはResponses API専用の最高性能版で、深い推論が必要なタスク向けです。
特に注目すべきは、GPT-5.4がフロンティアモデルとして初めてOSWorld-Verifiedで75.0%を達成し、人間のベースライン(72.4%)を超えた点です。デスクトップ操作の自律実行において、スクリーンショットの認識からマウス・キーボード操作まで、ソフトウェアを直接操作できる能力は、GPT-5.2の47.3%から大幅な飛躍を遂げています。
また、tool search機能の標準搭載も実用面で大きな進歩です。利用可能なツールの軽量リストを受け取り、必要なときだけツール定義を参照する仕組みにより、ツールを多用するワークフローでのトークン消費を劇的に削減できます。
Claude Opus 4.6の全体像 — 1Mコンテキストと自律エージェント
Claude Opus 4.6は、Anthropicが2026年2月4日にリリースしたフラグシップモデルです。最大の特徴は、1Mトークンコンテキストの正式GAにより、追加料金なしで100万トークンの入力を標準利用できるようになったことです。
Opus 4.6はAdaptive Thinkingを搭載し、タスクの複雑さに応じて推論の深さを自動調整します。単純な質問には即座に回答し、複雑なコーディングや分析タスクには内部で拡張思考を展開してから応答する設計です。さらにContext Compactionにより、長時間のエージェントセッションでもコンテキストの劣化を最小限に抑えます。
ベンチマーク面では、SWE-Bench Verifiedで80.8%を達成し、実際のGitHubリポジトリのバグ修正タスクで業界最高水準の性能を示しています。Terminal-Bench 2.0(ターミナル操作を伴うエージェントコーディング評価)でも65.4%のスコアを記録し、開発者ツールとしての総合力の高さを証明しています。
Claude Codeとの統合も大きな差別化要因です。hooks機構によるライフサイクルイベントの制御、deny-firstアーキテクチャによる承認フロー最適化など、開発者のワークフローに深く組み込める設計になっています。AnthropicはClaude Code公式ドキュメントでhooksの詳細な仕様と設計思想を公開しており、エコシステムの透明性も高く評価されています。
Gemini 3.1 Proの全体像 — マルチモーダルの王者
Gemini 3.1 Proは、Google DeepMindが2026年2月19日にリリースした最新フラグシップモデルです。公式ページによれば、テキスト・画像・音声・動画・コードの5つの入力モダリティにネイティブ対応した唯一のフロンティアモデルです。
コンテキストウィンドウは1Mトークンで、最大出力は64Kトークン。GPT-5.4やOpus 4.6と並ぶ大規模コンテキストを備えつつ、入力モダリティの幅広さで他を圧倒しています。GPTとClaudeがテキストと画像の入力に対応しているのに対し、Gemini 3.1 Proは音声と動画もAPI経由でネイティブに処理できます。
ベンチマーク面では、GPQA Diamondで94.3%という驚異的なスコアを記録し、専門知識を要する質問応答で3モデル中最高の性能を示しています。ARC-AGI-2でも77.1%を達成し、抽象的な推論能力で他のフロンティアモデルを引き離しています。LiveCodeBenchでのEloレーティング2887は、競技プログラミング領域での圧倒的な強さを示しています。
特筆すべきは、エージェントタスクでの性能です。APEX-Agents(33.5%)、MCP Atlas(69.2%)、BrowseComp(85.9%)とエージェント系ベンチマークで軒並みトップを獲得しており、自律的なタスク実行の分野でも急速にキャッチアップしています。
性能比較 — 5軸のベンチマーク分析
ここからは、具体的なベンチマークデータに基づいて3モデルを比較します。なお、各ベンチマークの詳細な方法論と最新のリーダーボードは公式サイトで確認できます。
推論・知識
GPQA Diamondは大学院レベルの専門知識と推論を問うベンチマークです。Gemini 3.1 Proが94.3%でトップ、GPT-5.4が92.8%で2位、Opus 4.6が91.3%で3位という結果になっています。ARC-AGI-2(抽象推論)ではGemini 3.1 Proが77.1%で大幅にリードし、GPT-5.4が73.3%、Opus 4.6が68.8%と続きます。
この差をどう解釈すべきでしょうか。GPQA Diamondでの2〜3ポイント差は、実務上の影響は限定的です。ARC-AGI-2での8ポイント差はより大きく、パターン認識や新規問題への適応力でGeminiが優位であることを示唆しています。ただし、ARC-AGI-2は人間のようなフレキシブルな推論を測るベンチマークであり、日常的なビジネスタスクへの直接的な影響は慎重に評価する必要があります。
コーディング
SWE-Bench Verifiedは、実際のGitHubリポジトリのIssueを解決する実践的なコーディングベンチマークです。Opus 4.6が80.8%、Gemini 3.1 Proが80.6%でほぼ同等、GPT-5.4はデータ汚染の懸念から公式スコアを公開していません。
SWE-Bench ProではGPT-5.3-Codexが56.8%で首位、Gemini 3.1 Proが54.2%で2位という結果です。Terminal-Bench 2.0(ターミナル操作を含むエージェントコーディング)ではGemini 3.1 Proが68.5%、Opus 4.6が65.4%となっています。
実務でのコーディング性能を総合すると、3モデルはほぼ拮抗しており、明確な勝者はいません。ただし、OpenAIがSWE-Bench Verifiedのスコア公開を見送った事実は注目に値します。データ汚染の懸念を自ら認めた誠実さとも取れますが、スコアが振るわなかった可能性も否定できません。
エージェント性能(Computer Use・自律タスク)
OSWorld-Verified(デスクトップ操作の自律実行)ではGPT-5.4が75.0%で人間のベースライン(72.4%)を超え、唯一の「人間超え」を達成しています。Opus 4.6は72.7%で人間と同等、Gemini 3.1 Proの公式スコアは未公開です。
一方、APEX-Agents(自律エージェントタスク)ではGemini 3.1 Proが33.5%でトップ。BrowseComp(Web調査タスク)でもGeminiが85.9%で首位を走っています。
Computer Useに限ればGPT-5.4が明確にリードしていますが、エージェント全般ではGeminiが強い結果です。Opus 4.6はClaude Codeエコシステムとの統合により、ベンチマーク単体では測れない実務上の優位性を持っています。これについては後述の「京谷商会の選定理由」で詳しく触れます。
マルチモーダル
テキスト+画像入力は3モデルとも対応しています。音声入力はGemini 3.1 Proのみネイティブ対応、動画入力もGemini 3.1 Proのみです。GPT-5.4はWhisperとの組み合わせで音声処理が可能ですが、APIレベルでの統合はGeminiに及びません。
マルチモーダル処理が業務の中心にある場合(動画解析、音声文字起こし+要約パイプラインなど)、Gemini 3.1 Proの優位は圧倒的です。テキスト+画像の範囲で十分なら、3モデルに大きな差はありません。
文章品質
ベンチマークには現れにくい指標ですが、実務で極めて重要な要素です。複数のブラインド評価で、Opus 4.6の文章は語彙の多様性、文のリズム、ニュアンスの表現力で一貫して高い評価を受けています。特に長文の構成力とトーンの一貫性は、ビジネス文書や技術記事の執筆で明確な差として現れます。
GPT-5.4は正確で読みやすい文章を生成しますが、Opus 4.6と比較するとやや均質的な印象を受けます。Gemini 3.1 Proは事実の正確性には優れますが、文章の「味」という点ではOpus 4.6に一歩譲ります。
価格比較 — コスト構造の徹底分析
標準API料金(1Mトークンあたり)
3モデルのフラグシップ版の標準料金を比較すると、入力トークンはGemini 3.1 Proが$2.00で最安、GPT-5.4が$2.50で2位、Opus 4.6が$5.00で最も高額です。出力トークンはGemini 3.1 Proが$12.00、GPT-5.4が$15.00、Opus 4.6が$25.00です。最新の料金は各社の公式ページ(Anthropic API料金、OpenAI API料金、Google AI料金)で確認できます。
Opus 4.6の料金はGPT-5.4の約2倍、Gemini 3.1 Proの約2.5倍です。この価格差は無視できません。月間1億トークンを処理する場合、Opus 4.6では入力だけで$500、Gemini 3.1 Proなら$200です。
長文コンテキスト利用時の追加コスト
ここに重要な差異があります。GPT-5.4は272Kトークンを超えるプロンプトに対し、入力料金が2倍($5.00/MTok)、出力料金が1.5倍($22.50/MTok)に跳ね上がります。一方、Opus 4.6は1Mコンテキスト利用時も追加料金なし。Gemini 3.1 Proも1Mまで標準料金で利用可能です。
長文コンテキストを日常的に使う場合、GPT-5.4の実効コストはOpus 4.6に近づき、場合によっては逆転します。京谷商会のkuevico基盤のように、大規模なコードベースやドキュメントを丸ごとコンテキストに投入するユースケースでは、この差は決定的です。
ファミリー展開と価格レンジ
GPT-5.4ファミリーは価格帯の幅が最も広く、nanoの$0.20/$1.25からproの$30.00/$180.00まで90倍の差があります。用途に応じた最適化の自由度はGPT-5.4が最も高いと言えます。
Anthropicのラインナップは、Haiku 4.5(軽量)、Sonnet 4.6(中間)、Opus 4.6(フラグシップ)の3層構造で、GPT-5.4のnanoに直接対抗するモデルはありません。ただし、京谷商会ではWorkers AI上のKimi K2.5をサブモデルとして検討しており、超低コスト帯はプロプライエタリAPIに頼らない設計が可能です。
キャッシュ・バッチ割引
3社とも入力キャッシュ(繰り返し同じプロンプトを送る場合の割引)を提供しています。Opus 4.6のプロンプトキャッシュは標準料金の10%で利用可能(90%割引)、GPT-5.4のキャッシュ入力は$1.25/MTok(50%割引)です。バッチAPIはOpus 4.6が50%割引、GPT-5.4も同等の割引を提供しています。大量バッチ処理を前提とした運用では、このキャッシュ戦略がコスト差を大きく左右します。
用途別の推奨モデル
大規模コードベースの開発・保守
推奨: Claude Opus 4.6
1Mコンテキストを追加料金なしで使える点が決定的です。数万行のコードベースをコンテキストに投入し、バグ修正やリファクタリングを依頼するワークフローでは、SWE-Bench Verified 80.8%の実力とClaude Codeのhooksエコシステムが組み合わさり、他のモデルでは再現しにくい開発体験を提供します。GPT-5.4は272K超で料金が跳ね上がるため、同じワークフローのコストが1.5〜2倍になります。
デスクトップ自動化・RPA
推奨: GPT-5.4
OSWorld-Verified 75.0%の実績は、Computer Useの分野でGPT-5.4が一歩先を行っていることを示しています。スクリーンショットの解析からGUIの直接操作まで、デスクトップアプリケーションの自律実行が必要なワークフローではGPT-5.4を選ぶべきです。Opus 4.6のComputer Use機能(72.7%)も十分に実用的ですが、この特定領域ではGPT-5.4に軍配が上がります。
マルチモーダル処理パイプライン
推奨: Gemini 3.1 Pro
音声・動画のネイティブ入力対応は、Gemini 3.1 Proの独壇場です。動画の内容要約、音声からの議事録生成、画像+テキスト+音声を組み合わせた分析など、複数モダリティを統合するパイプラインではGeminiが最適です。価格面でも$2.00/$12.00と3モデル中最安で、大量のマルチモーダルデータ処理にコスト競争力があります。
競技プログラミング・数学的推論
推奨: Gemini 3.1 Pro
LiveCodeBench Elo 2887、GPQA Diamond 94.3%、ARC-AGI-2 77.1%という数値は、純粋な推論能力と数学的問題解決でGeminiが抜きん出ていることを示しています。研究開発や学術的な問題解決が中心の場合、Gemini 3.1 Proが最も信頼できる選択です。
ビジネス文書・技術記事の執筆
推奨: Claude Opus 4.6
文章の質は最終的に人間の判断が必要な領域ですが、ブラインド評価でのOpus 4.6の一貫した優位性は無視できません。語彙の多様性、ニュアンスの表現、長文での構成力は、ビジネス文書や技術記事の品質に直結します。この記事自体がOpus 4.6ベースのkuevico基盤で制作されていることが、その証左です。
高ボリューム・低レイテンシのAPIコール
推奨: GPT-5.4-nano / Gemini 3.1 Pro
$0.20/$1.25のGPT-5.4-nanoは、分類・翻訳・定型回答など軽量タスクの大量処理で圧倒的なコスト競争力を持ちます。Gemini 3.1 Proも$2.00/$12.00と手頃で、より高い品質が必要な場合の選択肢になります。Anthropicにはこの価格帯の直接的な競合がないため、用途に応じてGPT-5.4-nanoとGemini 3.1 Proを使い分けるのが現時点での最適解です。
京谷商会がOpus 4.6を選んだ理由
ここからは、私たち京谷商会の実務上の判断を率直に書きます。
京谷商会はkuevico基盤のメインモデルとしてClaude Opus 4.6(1Mコンテキスト)を採用しています。93名のAIスタッフが日常業務に使用する中核モデルであり、この選定は純粋なベンチマークスコアだけでは説明できない、運用上の複合的な理由に基づいています。
理由1: 1Mコンテキストの無料化が運用コストを根本から変えた
kuevico基盤では、各AIスタッフがプロジェクトファイル・スタッフ個人ファイル・組織構造ファイルなど、大量のコンテキストを読み込んで動作します。これらのファイル群は容易に数十万トークンに達するため、GPT-5.4の272K超過時の料金2倍は致命的です。Opus 4.6は1Mまで追加料金なし、プロンプトキャッシュで90%割引という組み合わせにより、大規模コンテキスト運用のコストを劇的に抑えられます。
理由2: Claude Codeのhooksエコシステムとの統合
kuevico基盤はClaude Codeのhooks機構を権限管理の基盤として活用しています。SessionStart、ToolUse、NotificationSendなどのライフサイクルイベントをフックし、AIスタッフごとに異なるアクセス制御を実現しています。この仕組みはClaude Code固有のものであり、GPTのCodex CLIやGeminiのAPIでは同等の統合が困難です。
OpenAIのCodex CLIもhooksエンジンを導入していますが(v0.114.0〜)、Claude Codeのhooksが先行して成熟しており、私たちの運用では数か月の実績があります。乗り換えコストを考慮すると、現時点でのモデル移行は合理的ではありません。
理由3: 文章品質がコンテンツ事業の生命線
京谷商会はSEOナレッジベースを始めとするコンテンツ事業を展開しており、記事の品質は事業の根幹です。Opus 4.6の文章生成能力は、ベンチマークでは測定しにくいものの、日常的な記事制作で一貫して高い品質を維持しています。GPT-5.4も十分に優れていますが、トーンの一貫性と表現の多様性でOpus 4.6が上回るというのが、数百本の記事を制作してきた私たちの実感です。
サブモデルとしてのKimi K2.5
メインモデルはOpus 4.6ですが、全てのタスクにフラグシップモデルを使う必要はありません。京谷商会ではCloudflare Workers AI上のKimi K2.5をサブモデルとして検討しています。256Kコンテキスト、マルチターンtool calling、ビジョン入力をエッジで処理でき、既存のWorkers環境でそのまま動作することが魅力です。社内のAgent運用で7Bトークン/日を処理するワークロードをKimi K2.5に移行した場合、コストが77%削減されるというCloudflareの報告は、私たちの運用規模でも十分に実現可能な数値です。
ベンチマーク比較 総合表
最後に、この記事で取り上げた主要ベンチマークを一覧表にまとめます。
| ベンチマーク | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | 評価対象 |
|---|---|---|---|---|
| GPQA Diamond | 92.8% | 91.3% | **94.3%** | 専門知識・推論 |
| ARC-AGI-2 | 73.3% | 68.8% | **77.1%** | 抽象的推論 |
| SWE-Bench Verified | 未公開 | **80.8%** | 80.6% | 実践コーディング |
| Terminal-Bench 2.0 | — | 65.4% | **68.5%** | エージェントコーディング |
| OSWorld-Verified | **75.0%** | 72.7% | — | Computer Use |
| LiveCodeBench Elo | — | — | **2887** | 競技プログラミング |
| APEX-Agents | — | — | **33.5%** | 自律エージェント |
| BrowseComp | — | — | **85.9%** | Web調査 |
| 項目 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|
| コンテキスト長 | 1.05M | 1M | 1M |
| 最大出力 | 128K | — | 64K |
| 入力料金($/MTok) | $2.50 | $5.00 | $2.00 |
| 出力料金($/MTok) | $15.00 | $25.00 | $12.00 |
| 長文追加料金 | 272K超で2倍 | なし | なし |
| 画像入力 | あり | あり | あり |
| 音声入力 | なし(Whisper別途) | なし | あり |
| 動画入力 | なし | なし | あり |
| Computer Use | あり(75.0%) | あり(72.7%) | — |
2026年後半を見据えた展望
2026年3月時点では、3モデルに明確な「総合1位」は存在しません。得意領域が明確に分かれており、用途に応じた使い分けが最も合理的なアプローチです。
Gemini 3.1 Proの推論性能の急速な向上(ARC-AGI-2が3か月で2倍以上)は、Google DeepMindの研究力を示しています。OpenAIはComputer Useとtool searchで実務的なエージェント体験を先行しています。Anthropicは1Mコンテキストの無料化とhooksエコシステムで、開発者にとっての「一緒に仕事をしたいAI」としてのポジションを確立しています。
私たちは「最強のモデル」を探しているのではなく、「最も仕事がしやすいモデル」を選んでいます。その答えが、今のところClaude Opus 4.6です。GPT-5.4のComputer Useが成熟し、Gemini 3.1 Proの文章品質が向上すれば、この判断は変わるかもしれません。だからこそ、私たちはOpenAIとGoogleの動向を一次ソースから追い続けています。
フロンティアモデルの競争は、ユーザーにとってこの上ない恩恵です。3社が切磋琢磨することで、私たちが手にできるAIの能力は月を追うごとに向上しています。この記事が、皆さんのモデル選定の一助になれば幸いです。